Sophie Haskins



I’ve been looking to “figure out” my system for storing photos lately. I have an iPhone and send its photos to Google Photos, and a Sony mirrorless camera and store its photos in a local Adobe Lightroom directory. Both of these come with monthly subscriptions that I don’t really want to pay, especially because I don’t really care about the cloud features of either (I have a home NAS). The direction I’m experimenting with is Photos on a Mac with a handful of separate photo libraries (“personal”, pizzabox photos, very old/archive photos, homework for my online photography class) to make it easier to back up / move them around if they get too big.
That means I want to download all my photos from Google and import them. I ran in to a few obstacles doing that, and wanted to share the Unix command-line tricks I used to get around them!
Disclaimer
Since I’m posting “something fun I did on the command-line” on The Internet (a place notoriously unforgiving to any imperfections), I want to lay out some things before we start:
- This is not the most efficient / best / easiest way to solve this problem, in terms of keystrokes, CPU time, memory usage, SSD wear, wall-clock time, open-source license of tools involved, viability for people using Be OS on the desktop in 2019, or theoretical cleverness
- I tried a bunch of things that didn’t work while I was building this up. I’m only showing what worked, but rest assured, I don’t get things right on the first try
- I also don’t have any of this memorized - I did a lot of Googling and manpage reading
- I know that I can turn off the auto-unzip-and-delete in Safari, I just hadn’t done it yet b/c I recently wiped this computer
I’m sharing this because I like talking about the thought process behind solutions. It’s not a “how-to”, it’s a story.
Downloading
Google lets you export your data with their Takeout service. My photos were a total of ~35GB, which means that they split it up in to multiple 2GB chunks. This was pretty annoying - even with 100 Mbit/s Internet that’s a minimum of 45 minutes to download it all! Plus, I needed to keep clicking the next file once each finished:
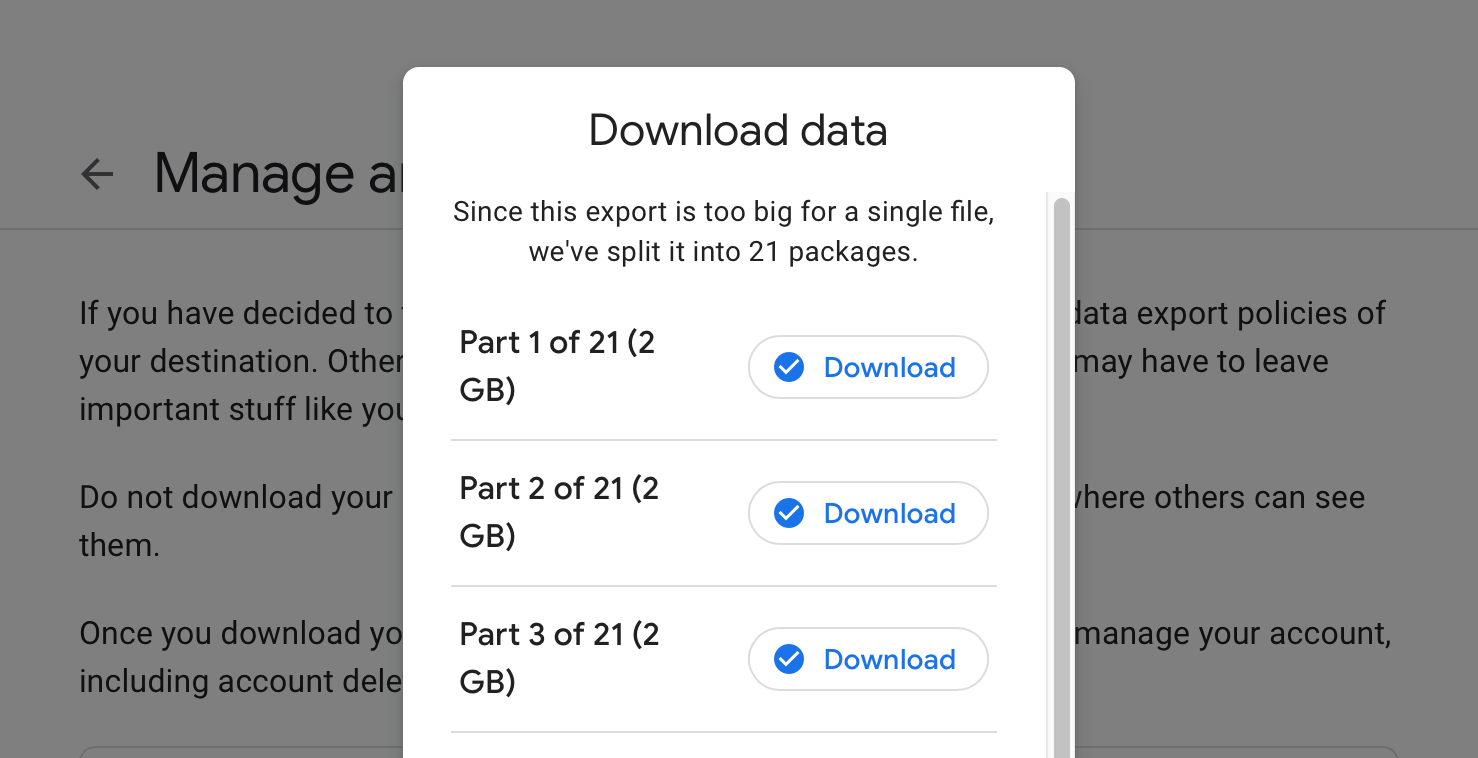
Each part of the download was named something like takeout-20191105T000000Z-001.zip, and there were 21 of them. Before I start importing files to the Photos app, I want to make sure I downloaded all 21 zip files. It’s easy to verify that I downloaded some 21 files - after all, there are 21 items in my Downloads directory now! But unforunately, Safari immediately unzipped the files after downloading and deleted the zip files. The resulting directories were all named like Takeout-2:
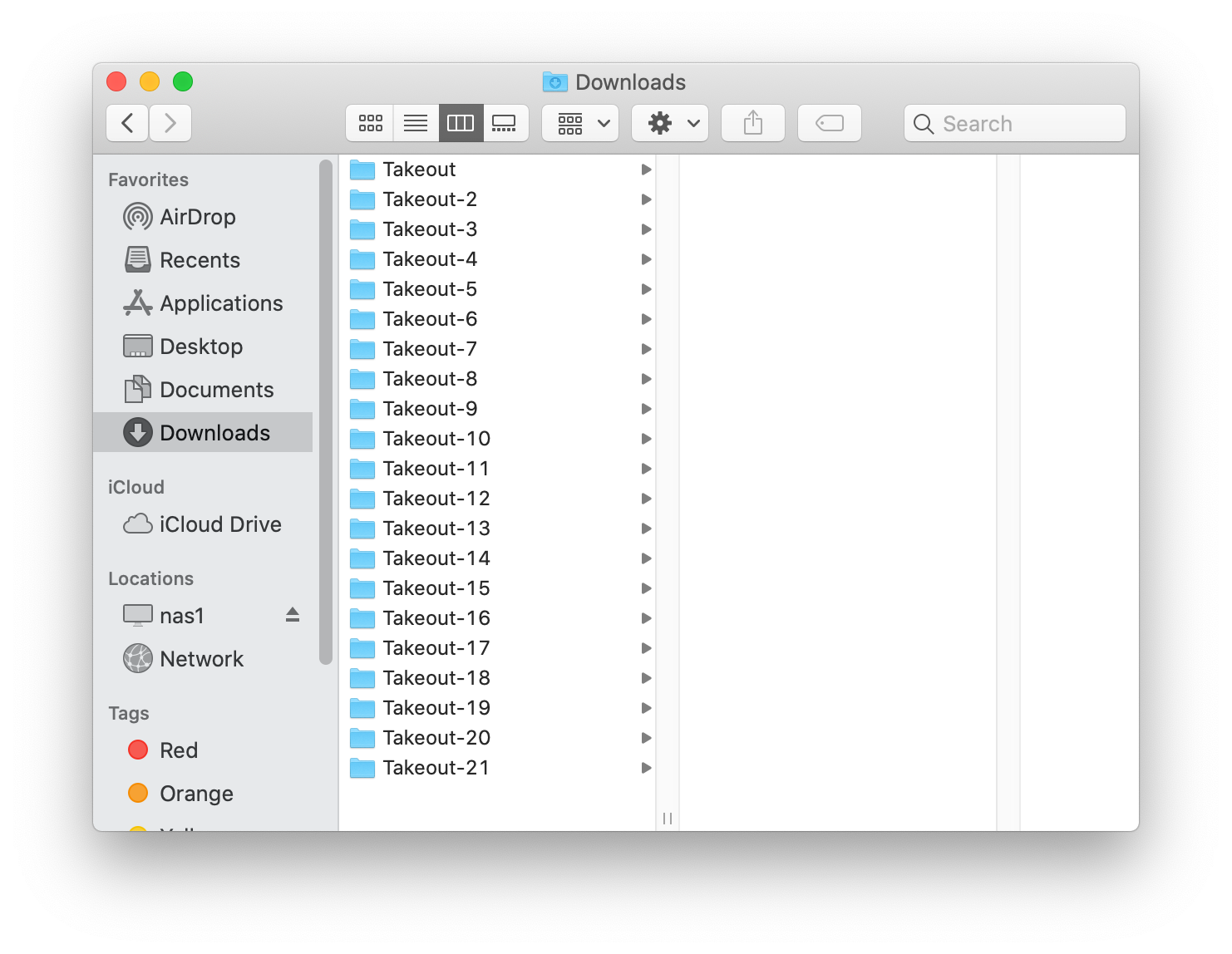
So as long as I have no duplicate directories, we’re fine, right? Unforunately, no - the numbers here are added by the Finder as it unzips, because each zip file had a folder called “Takeout” in it. So, we’ve reached the problem - how can I determine if I accidentally downloaded any zip files twice (and thus missed some other zip)?
What do I have?
My first step was to figure out what I have. It’s a bunch of pictures, living in files that look like: ./Takeout/Google Photos/2019-05-07/IMG_1277.JPG. I don’t want to look at them all and compare visually, since there’s so many!. Even asking a computer to compare each file against eachother would take a very long time. Instead, I used md5 (manpage) on each file to calculate a hash. The command I ran was:
find . -type f -exec md5 {} \; > md5s
There wasn’t anything else in my Downloads directory at the time, so the find . type f lists all the file paths of the photos. Using -exec md5 {} \; tells the find command to run md5 FOO for each FOO that it found. If I were a super command-line-witch, I might have piped this in to some of the next commands, but for me its nice to store the intermediate results in to a file md5s so I can try out a bunch of approaches. The resulting lines in the md5s file look something like:
MD5 (./Takeout-2/Google Photos/2017-12-18/IMG_0555.MOV.json) = 81156046955443c089ae4fc74100998f
What files are duplicates?
I definitely expect some duplicate photos - maybe ones I uploaded to Google twice, or exist in multiple album folders, etc. If this weren’t the case, we could be done after doing something like
awk -F= '{print $2}' md5s | sort | uniq -c
In that command, -F= says “split up on the = character”, so awk sees the fields of each line from md5s as MD5 (./Takeout-2/Google Photos/2017-12-18/IMG_0555.MOV.json) and 81156046955443c089ae4fc74100998f. The '{print $2}' says “just show me the second field” (ie, the 81156046955443c089ae4fc74100998f), and sort | uniq -c shows me the count of each unique value. If any hashes show up twice, we probably have duplicates! We can find the ones with two entries by adding a little extra to the pipeline:
awk -F= '{print $2}' md5s| sort | uniq -c | awk '$1 > 1 {print $2}'
Here we do a second awk on the output of uniq -c that, when the count is more than 1 ($1 > 1 ), prints out the hash ({print $2}).
But like I said, I expect duplicates. We’re not trying to dedupe the files per-se, but make sure that I didn’t duplicate an entire folder. If we look at all the duplicate files, we should be able to tell if they’re from duplicate folders if everything after the Takeout-2 part of the filename is duplicated (for example, if I had downloaded the same zip twice, and it unpacked in to Takeout-2 and Takeout-3). The awk above gets us the hash of the potentially duplicated files, but not their full paths. To get their paths again, we can search back into the md5s file:
awk -F= '{print $2}' md5s| sort | uniq -c | awk '$1 > 1 {print $2}' | xargs -n 1 -I '{}' grep {} md5s > dupes
Here is the fun stuff! Piping to xargs lets us send the hashes right back to a grep to get their full entry from md5s, path and all. The important parts here are that we tell xargs to only do one input at a time with the -n 1 (as opposed to doing a big batch of them, which wouldn’t be a valid regexp), and then tell it where we want that one value to go in the resulting command with the -I '{}' grep {} md5s. For each hash piped to xargs, it will run
grep abcdef0123456789 md5s
This lets us build up dupes, a version of md5s that only has potentially duplicated files in it.
Final stretch
Awesome! So we know that everything in dupes has a matching md5 hash to some other file - how do we tell if it looks like it’s from the same zip file? If it were, the path (minus the Takeout-2 part) will be the same, so lets grab just that and see if we have any duplicates:
awk -F/ '{print $4 "/" $5}' dupes | sort | uniq -d
Since all the paths start at my downloads folder, if we use -F/ to tell awk to split on the / in the path names, I can print out just the latter bit. For:
MD5 (./Takeout-2/Google Photos/2017-12-18/IMG_0555.MOV.json)
we end up printing out:
2017-12-18/IMG_0555.MOV.json)
Sending that in to sort | uniq -d uses the uniq program to tell us “are any two lines in this file the same”.
My luck was good! There were no duplicate zip files unpacked here, so I have all the photos!
Combine the directories
Since we now know there’s no duplicate paths, I want to combine all the parts in to one big folder. There’s a few ways to do this, but it turns out that “combining a bunch of directories in to one” is something that rsync is good at! I did:
mkdir combined
for dir in `ls | grep Takeout`; do rsync -avh $dir combined; done
The ls | grep Takeout gives me the full list of unpacked directories (if I just do ls Takeout* the shell unhelpfully expands that wildcard and shows me the contents of each; if I only did ls then I’d have picked up md5s and dupes). We loop over those, and rsync -avh $dir combined to copy it from the source dir to combined. Now, combined has one big directory of the full dump from Google Photos!
Sophie this is overkill
OK so now that I’m done, I see some ways I could have made this faster. I didn’t need to grab the md5s at all - the paths should have been sufficient! At the beginning I wasn’t sure what the structure of the directories was, so I began with md5. Armed with knowledge about the structure, though, I bet we could have done something like:
find . -type f | awk -F/ '{print $4"/" $5}' | sort | uniq -d
and realized things were a-ok. Maybe you have ideas for other cool ways to check it out!